I was asked to be an expert witness for a court case last week. There was some video footage from a CCTV camera of an individual walking across a street from some distance away and the question I was being asked to provide an opinion on was, “Is it possible to identify the individual on the basis of his gait pattern?“.
There are, of course a number of University departments working on related issues (that within Computer Vision at the University of Southampton is a good example) and some evidence of commercial interest. Every so often the concept bubbles into the popular science magazines. (There is now even an Android app that claims to be able to identify a person from the accelerometer data from a smartphone carried in their pocket while they are walking, but that’s another story).
I’ve generally been rather dismissive of these claims. I strip people down to a pair of shorts, stick retro-reflective markers over anatomical landmarks, ask the person to move in a particular fashion along a clearly marked walkway and then capture the movements with ten extremely high resolution cameras pointing directly at them. It often amazes me how little evidence there is of difference from normative reference data even for individuals with quite marked pathology. If I can’t detect such clear differences under such standardised conditions using such specialised equipment how can anyone suggest that they can recognise a healthy individual, presumably with a gait pattern within the normal range, on the basis of a video image of them walking down the street fully clothed?

Julius Caesar, Museo della Civiltà Romana by Bushtick 
And yet in Shakespeare’s Julius Caesar, Cassius says to Casca when he sees a figure approaching, “Tis Cinna. I do know him by his gait“. In Melbourne my office was by a corridor and it was generally possible to identify which of my colleagues was approaching along it by the sound of their footsteps. Our common experience is that we do recognise people at least partly by their gait. If gait patterns are so characteristic why is it so difficult to pick up abnormality in clinical gait analysis.
I suspect the answer is partly that gait is so varied and characteristic. There is much more variability in normal walking than we appreciate. The creation myth of clinical gait analysis is that there is a well-defined pattern of normal walking and that our patients exhibit patterns that differ from this. The longer I think about this idea the less I believe it is true. When we tidy up our normative data by only plotting one standard deviation limits we get reasonably tight normal ranges but this is at the expense of excluding a third of the data (the +/- 1 SD limits only include 67% of the data by definition). If we plot two standard deviations, which represent 95% of the data, then we get much larger bars. Maximum knee extension in stance, for example varies between 5° of hyperextension and 18° of flexion across the healthy population (see figure below).
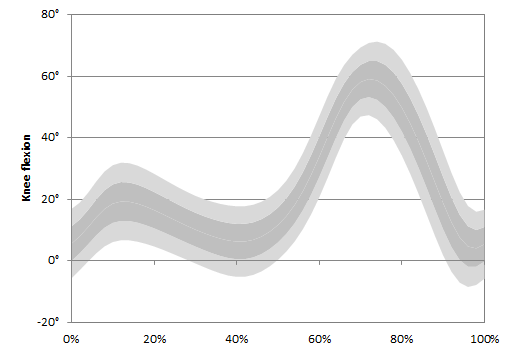
The reason why it is so difficult to identify gait abnormality among our patients is at least partly because the normal variability between individuals is so large. Maybe on this basis gait as a biometric identifier is not quite so fanciful (although I still have reservations as to whether it will ever work on the basis of CCTV footage recorded in town centres or airports). Perhaps more importantly, should be studying the characteristics of inter-person variation in gait patterns more closely in order to understand normal walking. In amongst all that variability are there specific characteristics that are invariant? If there are what does that tell us about the requirements of healthy walking? Gait variability within individuals is now seen as providing information about stability and by extension to falls risk (e.g. Callisaya et al. 2011). Maybe we should be paying more attention to gait variability between individuals.
PS Of course the other important factor in recognising people by their gait in every day life is the wide range of information we use to do so. When I recognised people by their footsteps from my office it was probably more to do with the sound that different footwear made as it was to do with temporal-spatial characteristics. One particularly famous CP surgeon was easily identifiable – partly from a mild asymmetry in his footfall pattern but more importantly from the characteristic jangle of coins and or keys in his pocket.


